Presentation - Fixing Careerious: From C#/.NET to Ruby on Rails
May 12, 2009 13:56

Last Thursday (May 7 2009) I gave a presentation at the Ruby on Rails Project Night. My presentation was last, the other presentations had been quite technical, and (more significantly) there had been free beer available for an hour and a half. So I decided to tell a story. Paul Martin managed to get some video footage of the presentation, so I've mixed in some clips with the regular slides and notes.
This is the story of a project I did last fall and winter, where I converted an old and crusty C# / ASP.NET web application into a cleaner and better Ruby on Rails application.
Background

The company who hired me for this gig was Careerious (now known as ClearFit). They are an offshoot of an enterprise venture that does personality assessments for HR departments of large organizations. Careerious was designed to be a web-based startup, selling a subscription-based service to smaller companies.
At the heart of the Careerious system is a job seeker / employee questionnaire with 160 questions, the answers to which are analysed into a 22-trait PersonalFingerprint. These traits include things like Openness to Change, Stress Tolerance, Interest in People, etc. Jobs have similar JobFingerprints, with the same traits.
The core of the application involves matching the PersonalFingerprints with JobFingerprints. Jobs and candidates are also matched on up to 25 other skill and experience traits, such as education history, languages spoken, willingness to relocate, and so forth.

The application has tools for managing candidate searches as well as current employees. It also automatically generates various PDF reports based on the PersonalFingerprint and job match criteria.
So it's a pretty cool application, and the company has smart founders - definitely good potential as a startup.
The problem was with the the original software. It had been done in classic C#/ASP.NET by an external vendor, who had adapted it from a pre-existing municipal planning application. It had taken them two years to build it to its current slow and buggy state.

(I put this fake 'Successories' poster together just for the presentation - follow the link for a bigger version. The fine print says: "Enterprise Software: It's really complicated, it took forever to build, and it cost a whole lot. It must be better.")
The main problem is that they had brought in an Enterprise vendor to build software for a startup. Enterprise software is all about fixed requirements, big budgets, accountability, plausible deniability, and a slow steady and conservative approach. Startups change their business model every quarter, their revenue projections every month, their partnerships every week, and their minds every day. The key for startup software is to be quick to build and easy to modify and maintain.
The original vendor was not really suited for this kind of startup work. They also seemed to have grown tired of the project and assigned less experienced developers to it.
So by the fall of 2008, the founders were trying to run a startup on a barely functional application. Simple layout changes would take weeks to deliver at a huge cost. The founders, smart people but not heavily tech-focused, had become worn out from dealing directly with this vendor, so they hired a CTO: Robert Nishimura. He looked at the situation and thought it might be worth ditching everything and starting again with a more agile toolset and open-source technologies. He looked into Rails and got in touch with me. It seemed like a cool project, so I said okay. I remember back in 2005/2006 how much fun it had been to convert messy old Java and Notes applications to Ruby on Rails - and this seemed like this would be a similar kind of project. I also enjoy cleaning up other people's messes - it makes me feel so much better about my own programming ability.
The Translation Process
In mid October of 2008, they gave me- the URL for the live site (yup the live site - no test site existed) and some logins for test users
- a 200MB dump of the MS SQL Server Database, which had been converted to PostgreSQL
- the complete C#/ASP.NET source code

The day that I got all of this material from them, I set up an empty Rails application, copied over all of the images, stylesheets, and JavaScript libraries from the ASP.NET application, did 'View Source' on the first few pages of the Candidate and Employer registration workflows, and copied the screens over. There was no database or anything, but the navigation was correct, the rollover effects worked, and the pages looked identical to the ASP.NET version. I deployed the application to my server and on the second day of working on the application, I sent them an email saying "Check out careerious.shindigital.com".
It's good to start a customer relationship - especially one whose previous vendor experience wasn't very good - by blowing their minds.

One thing that helped me get started quickly, is that I never actually ran the C# code - thus saving me the time and trouble of setting up Visual Studio and MS SQL Server and getting this crufty application to work on it. I spent several years working in Java and C# is so close to Java that I was able to understand it easily.
The development process was pretty basic. I went through the workflow and set up models and controllers as they came up, making new tables and copying the data across while cleaning it up.

(Note: it turns out there's a bug in my Ruby code. Can you find it?)
Most functions ended up being a lot shorter than the original. Some of this was just Ruby's succinctness, some of this was also Rails features like ActiveRecord. A lot of it was the quality of the original code: there were many places where I replaced hundreds of lines of case or if/else statements with a hash and a loop.

Because of the extensive refactoring work I did, there weren't too many places where I could compare directly between C# and Ruby versions of exactly the same code. Here's one though: the JobFingerprint calculations - take in exactly the same information and return the same results. The original took 480 lines of C#, while mine took 176 lines of Ruby.

We did add some new stuff, though. First was an Admin interface for letting the owners see and manage the application data. The original application was the bad kind of WYSIWYG: even if you're the owner, you only get what any regular user can see. So Paul Doerwald built a cool Scaffolding-like RESTful framework for displaying and managing all of the application data.
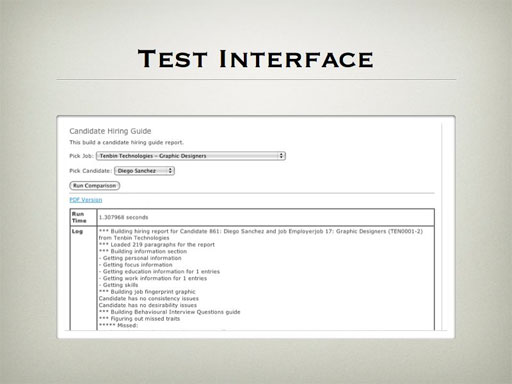
The other thing we added was a testing interface. There are some complicated proprietary algorithms at the heart of the Careerious application, and in the previous version these had been working in a black box. The founders gave details to the vendor, but the only way that they could tell if the calculations had been done correctly was to set up fake candidates and jobs and see how they behaved in the live application.
So I built a TestController. I had wrapped all of the key functions into their own commands, and made sure there were non-destructive display-only options for running these commands. I then built pages where you could select from the live data and then run the command. In the command code itself, I built up an array of strings that tracked the entire logic flow and results, which I could then show on the results page, along with all of the appropriate context information and the run time. The owners could now just look at these pages and see whether the calculations and logic were working correctly - and I could use them to fine-tune the performance and behaviour against real application data.
Some WTFs
Okay, so now on to the fun stuff. Of course any large complicated application is going to have problems and strange messy code and bad data - I've certainly written my share over the years - but this one was more messed up than most that I've seen. I guess it isn't very nice to pick at other people's code, but it's so much fun - and might even be educational.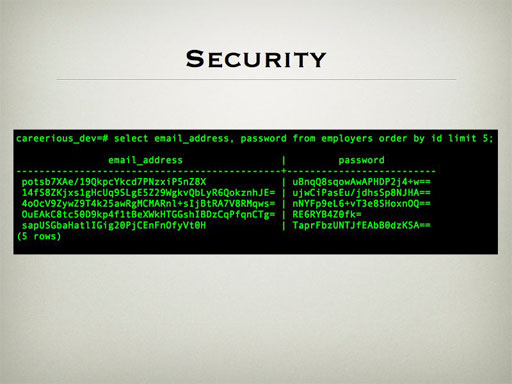
One of the messy things the original vendors had done was create their own encryption system, compiled into a DLL, and applied it against every user's email address and password. It wasn't a common encryption system like SHA1 or MD5, so we were worried we would be stuck having to ask everyone for their email addresses or give them all new passwords.
Then one day I was looking through the messaging framework - the application keeps track of every message that it sends out. I noticed that this included the 'Welcome to Careerious' messages sent out when a user first registers - and hey, look at this...
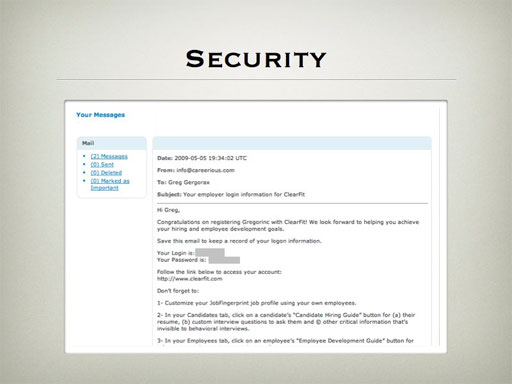
That's right, the passwords that had been carefully secured with a custom encryption system were displayed in plain text in another table. Even better, for candidates the username was their email. So we were able to get almost everybody's email addresses and passwords simply by running some scripts through the database.

The database was messy. A lot of tables had columns with no data, or with irrelevant data. There were entire tables that weren't being referred to by any of the code. It felt a bit like an archeological dig: deep down, underneath the commonly-used tables, there were remains from the original municipal planning application, like the entire help file (one table row per sentence, which must have been fun to work with) and a set of tables describing different types of concrete.
When I first started working on it, the database had 250 or so tables, and the database dump was 187 megabytes. As of today, the database has 56 tables, and the latest dump (including six months of new data) is 25 megabytes.
The biggest issue was that logging in for some users could take over a minute - and this wasn't just waiting for some kind of timeout, but a minute of 100% CPU usage on the server. Fixing this was obviously one of the priorities in the rewrite. It turned out that it wasn't the login process at all, but it was the sorted list of candidates that was the default landing page for employers after they logged in. The sorting is fairly complex, and includes cross-references against 25 skill and experience values for every candidate, among other criteria. The original application wasn't set up to use an Object-Relational Mapping such as NHibernate - instead, every time a piece of information was needed, a new database query was called. So for an employer with 135 candidates, loading the page would take over 3000 queries.
They tried to break this process out into two tiers, one which would store cached scores and another which would read them. However, that didn't work out too well either:
(It was a high point of my year to see the audience's faces when this slide came up. You can hear the reaction in the clip. People actually stood up in the back of the room to see it better.)
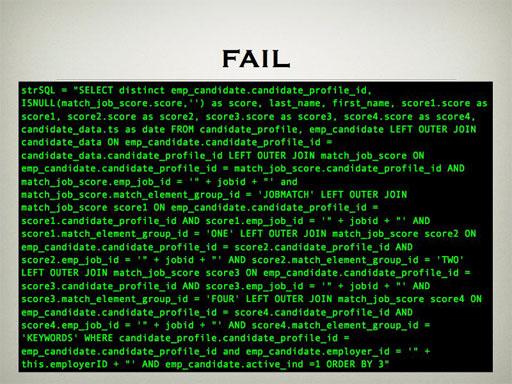
This query took 10 seconds to run directly in the psql client on my Core 2 Duo machine. I cleaned it up to return five rows per candidate rather than one hybrid row, and it took 0.15 seconds.
Also, as I say in the video clip, the most powerful optimization you can do is to go to the owners and explain the situation and ask if they really need this functionality - and it turned out that most of the complexity they were trying to address here wasn't even required anymore.
I was able to get the minute-long initial score calculations down to about one second, so we didn't need to worry about caching. We're continuing to optimize this and are looking at a more rigourous pre-calculation approach down the line to handle bigger volumes.
Conclusions
(As a programming presenter in 2009, I am contractually obligated to show this cartoon.)
The new version is definitely better. We didn't hit the initial December 1 deadline - but did get it live by early January.
It is now a 'real' contemporary Rails application. We have tests, we have a staging server as well as a live server, both hosted on EC2 (another cool thing that Paul Doerwald set up for us), the code is being kept in a private GitHub repository, and we're using LightHouse for issue tracking. It is now on a strong enough foundation that we've recently launched a redesign.

A few lessons I learned from this project:
As I said earlier, don't bring an Enterprise approach to a startup. It scares the vendors and can ruin the startup.
Working on this old-style code reminded me of how much better it is to work in Ruby and Rails. There's a lot of talk in the community about the various ways that Ruby, Rails, Merb, etc. can be better, and of course there's room for improvement - but Ruby and Rails are still light-years ahead of what many if not most programmers have to deal with day-by-day, and we should remember that before we complain too much.
- I also did some 'wc' juggling and came up with this somewhat arbitrary table:

I didn't include XML files in the count for the C# version, and similarly I didn't include tests or fixtures or migrations in the count for the Ruby version. On the other hand, we could have had even less code in the pages if we had used HAML, but we saved a lot of time by being able to copy-and-paste from the original ASP pages. Also, there would be less C# code if the developers had used better techniques.
In the end, it was an interesting project to work on, and a fun presentation.
If you want to find out more, I can be reached through the 'Contact Me' form on my site http://www.shindigital.com, or on twitter at @ajlburke.
You should also check out ClearFit - they have a unique product and - now that they have working software - are starting to go places.